网络爬虫第二篇:网页解析 学习BeautifulSoup库、lxml库和XML语法技巧
上一篇我们总结了下
request库,为这篇网页解析做好了数据准备。 这篇是学习bs4和lxml的过程,还包括了xml语法编写的技巧 水平有限,多多交流
一、关于BeautifulSoup库
BeautifulSoup解析网页结构树,最终提取标签、属性、元素功能强大,可使用多个解析器,如
html.parser和lxml
二、BeautifulSoup的使用
1.导入BeautifulSoup,创建解析对象
#导入模块
from bs4 import BeautifulSoup
#创建对象,html为网页数据(代码见上一篇),lxml为选择的解析器类型
bshtml = BeautifulSoup(html,'lxml')
2.提取特定标签或属性,并输出列表
最常用的函数:
findALL(tag,attribute):提取全部find(tag,attribute):提取一个ojb[i].get_text():提取文本,一般提取最终数据时才用 用法灵活,可组合布尔值、正则表达式、lambad表达式
#查找特定标签或属性
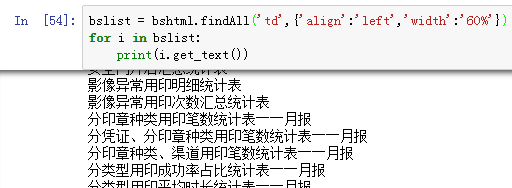
bslist = bshtml.findAll('td',{'align':'left','width':'60%'})
#统一查看某个属性
bslist.attrs['td']
#配合正则表达式使用
import re
bslist2 = bshtml.findAA('title',re.complie('.*?')
#输出列表
textlist = []
for i in bslist:
textlist.append(i.get_text())
print(textlist)
结果如下图:
三、关于lxml库
该库用于处理XML和HTML、功能超强
学习坡度大、纯种python API优势明显
分享:lxml库用法详解
分享:xpath语法规则详解
四、lxml库的使用
1. 导入lxml库,创建解析对象
from lxml import etree
html = html.encode('gbk')#注意数据的编码
xml = etree.HTML(html)
2. 提取选定标签或属性,输出列表
常用对象方法:
etree.html(html):解析网页代码etree.pare(file):解析网页文件ojb.xpath:提取指定标签或属性ojb[i].text:用于提取单一标签的文本
#查找标签列表
xmlist = xml.xpath('//a')
#查询属性列表
xmlist = xml.xpath('//a/@title')
#输出结果列表,属性列表可直接输出,无须此步骤
textlist = []
for i in xmlist:
textlist.append(i.text)
print(textlist)
结果如下图:

小技巧:快速编写XML语句的技巧
使用XML固然更高效,但编写规则真心费事啊~ 所以我需要浏览器的F12来帮忙! 这个方法只是参考,非100%正确
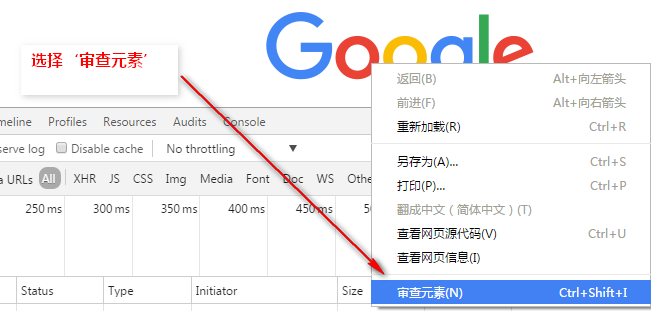
1、使用F12打开后,选中目标,右键选择‘审查元素’:
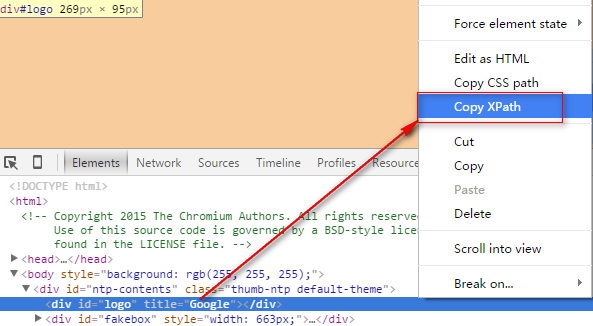
2、浏览器自动标记到代码位置,右键选择‘Copy XPath’
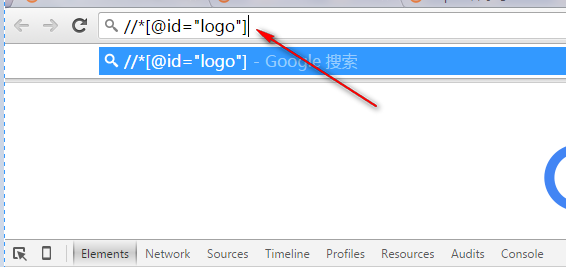
3、查看XML语句是否符合要求,自行调整
下一篇:我将尝试实现一个爬虫实例
本篇内容和图片属于本博客所有,转载请注明出处和作者
