今天开始一点点总结自己的scrapy学习过程,年龄大加上时间少断断续续的。
这个过程中学习了网友Jack-Cui和静觅博客的部分内容和技巧,非常感谢!
采用pycharm + Anaconda建立环境
之前写过一片关于Anaconda安装scrapy的文章,但是写爬虫最好还是用个IDE吧
pycharm不二选择,不过和谐版本需要自己想办法搞定啦~~这里不多说。。。
安装好pycharm后,记得选择python版本为Anaconda的!
怎么设置自行百度,这里算是有个懒癌的办法就是把默认版本设置Anaconda的,这样以后新建项目均采用默认的python版本了
scrapy处理流程的简易说明:
- 选定目录,新建一个scrapy项目
- 在items.py文件中定义目标数据字段
- 在spiders文件夹中编写你自己的爬虫
- 在pipelines.py中设置存储数据的过程
- 在setting.py中设置项目,可自定义内容,属于非必须步骤
一、创建scrapy项目
-
进入你准备存放项目的目录,按住shift+右键,
选择在此处打开命令窗口,进入cmd界面。
 若你使用pycharm的话,可以添加目录后,再运行工作台也可
若你使用pycharm的话,可以添加目录后,再运行工作台也可 - 使用scrapy固定命令,创建新项目
命令格式:scrapy startproject 你的项目名如demo
使用该命令后会创建如下文件结构:demo/ scrapy.cfg demo/ __init__.py items.py middlewares.py pipelines.py settings.py spiders/ __init__.py ...此处为自定义爬虫部分scrapy.cfg:项目的配置文件
demo/:项目的python代码部分
demo/items.py:配置项目的目标数据字段部分
demo/middlewares.py:配置项目的中间件,属于高级设置
demo/pipelines.py:配置项目的管道存储部分
demo/settings.py:配置项目的设置部分
demo/spiders:配置项目的爬虫代码部分,属于核心设置 - 为方便调试scrapy,建议独立写个py文件,运行调试,代码如下:
from scrapy.cmdline import execute
#第三项是爬虫名字,此命令可以启动爬虫!!
execute(['scrapy', 'crawl', '你的爬虫名'])
二、初步分析目标网站
- 进入cmd工作台,使用scrapy固定命令:
scrapy shell “目标网址” -
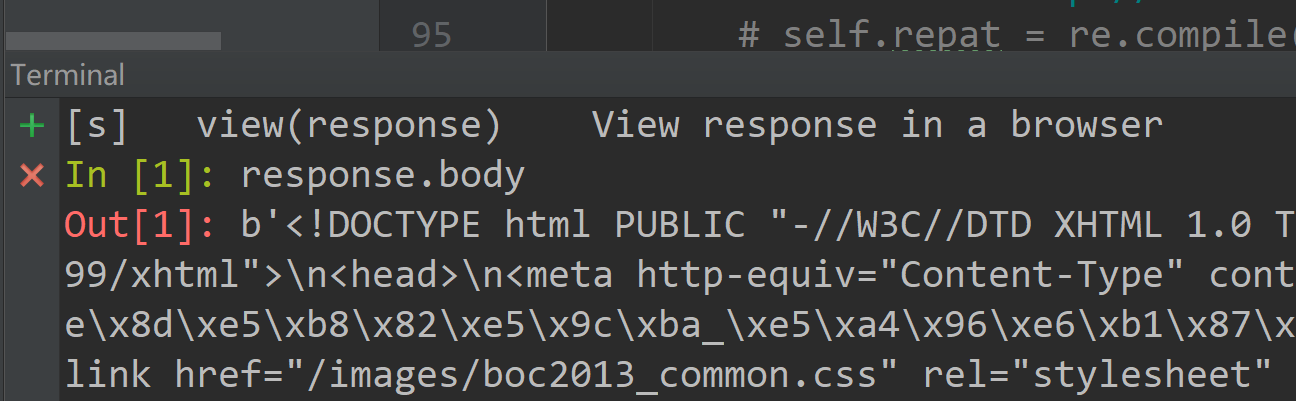
请求后得到反馈的response,使用
response.body查看网页代码:
- 提示:此处有可能看到utf-8编码方式而非gbk,这样一般并不影响后面的分析:
- 分析网页结构,提取目标字段
直接在控制台使用scrapy命令来分析网页,真的会亮瞎你的眼,保证看得你那叫个凌乱~~
所以我个人推荐:
首先利用谷歌浏览器或其他能使用F12的来分析网页结构和目标字段的XPath提取规则,之前的笔记里写过的
然后配合cmd控制台进行验证规则是否可行,效率非常快。 - 验证提取规则是否能正常使用
其中有4中常用的方法:这几个方法非常非常重要!!!
1.xpath():返回selector列表,每个selector是xpath表达式选择的节点
如response.xpath('//td')
2.css():返回selector列表,每个selector是css表达式选择的节点 如response.css('')
3.extract():返回xpath表达式所提取的unicode字符串
如response.xpath('//td/text()').extract()
4.re():返回xpath提取的,且由正则表达式处理后的unicode字符串
如response.xpath('//td/text/()').re('\d+')
- 将验证成功的xpath表达式记录下来备用,后面爬虫全靠这个!
三、编写item.py:设定目标存储字段item
从这里开始编写scrapy框架内容,首先是item.py里创建字段字典类
如下面代码,其中name、age、sex都是定义的目标字段:
import scrapy
class DemoItem(scrapy.Item):
name = scrapy.Field()
age = scrapy.Field()
sex = scrapy.Field()
四、编写setting.py:设定项目参数以及自定义变量等
- 首先可注释最后几行代码,这个据说可以利用Scrapy缓存之前的Requests。再次请求时,若存在缓存文档则返回缓存文档,无需反复到网站请求,是不是很人性的设计~
# Enable and configure HTTP caching (disabled by default) # See http://scrapy.readthedocs.org/en/latest/topics/downloader-middleware.html#httpcache-middleware-settings HTTPCACHE_ENABLED = True HTTPCACHE_EXPIRATION_SECS = 0 HTTPCACHE_DIR = 'httpcache' HTTPCACHE_IGNORE_HTTP_CODES = [] HTTPCACHE_STORAGE = 'scrapy.extensions.httpcache.FilesystemCacheStorage' - setting中常见的设置选项,可自定义添加设定,但不是必须的,根据自己的需求来即可。
BOT_NAME:自动生成的内容,根名字;
SPIDER_MODULES:自动生成的内容;
NEWSPIDER_MODULE:自动生成的内容; ROBOTSTXT_OBEY:自动生成的内容,是否遵守robots.txt规则,这里选择不遵守;
ITEM_PIPELINES:定义item的pipeline;
COOKIES_ENABLED:Cookie使能,这里禁止Cookie;
DOWNLOAD_DELAY:下载延时,这里使用250ms延时。
#以下是imagespipeline的设置,用于设定图片保存路径
IMAGES_STORE:自定义的图片存储路径;
很晚了,今天先到这里,明天继续爬虫和管道部分的总结,这才是核心内容,而且有些地方不好理解。
声明:本文为作者原创,未经同意严禁转载
