上一篇写到了items.py和setting.py的部分,也就是分别设置好了你要爬的内容和你的项目属性
下面呢就可以写最核心的部分了:爬虫代码spider.py和存储管道代码pipeline.py
之前介绍过python的yield、python面向对象的编程、以及scrapy的流程图,其实是为了此处做准备的!
务必先基本了解前面写的这几部分内容,不然自己写的代码自己都不知道是干嘛的~,岂不是很傻很天真?
这里的代码并不好注释,接下来用demo的代码来逐步说明,仅供参考思路,代码无法直接运行的
一、编写items.py的代码
'''items.py文件'''
import scrapy
#创建一个目标字段类,类似于字典的结构
class DemoItem(scrapy.Item):
url = scrapy.Field()
name = scrapy.Field()
age = scrapy.Field()
sex = scrapy.Field()
二、编写自己的spider代码:
'''自定义的demospider.py,此代码仅演示流程,无法运行'''
import scrapy
#导入项目的items目标字段类
from demo.items import Demoitem
#新建自己的爬虫类
class DemoSpider(scrapy.Spider):
#必要步骤:定义自己的爬虫名字,具有唯一性!
name = '你的爬虫名字'
#定义一些常规实例属性,也可以定义为类属性,根据情况来吧
def __init__(self):
self.allowed_domains = ['xxx.com']#注意此处指定爬虫范围有技巧,一般设定为域名,不带http前缀或不带WWW
self.start_urls = ['http://xxx.com']#指定最先开始爬的网址
#定义启动请求函数,如果不定义它,则默认从属性strat_urls开始
def start_requests(self):
#提交一个request请求并带入到解析器parse1来提取内容
yield scrapy.Request(url = self.start_urls[0],callback=self.parse1)
#定义一个解析器parse1
def pares1(self,response):
#解析返回的response,并提取内容
urllist = response.xpath('//@href').extract()
for i in urllist:
#实例化定义的item类
item = Demoitem()
#保存提取的内容,如url
item['url'] = urllist[i]
#进一步提交爬出的请求,并由解析器parse2来分析提取其他内容,注意此处是将创建的item实例作为参数带着走的!
yield scrapy.Request(url = urllist[i],meta={'item':item},callback=parse2)
#定义下一个解析器parse2
def parse2(self.response):
#将带来的参数读出来
item = response.meta['item']
#解析返回的response,并提取其他内容
namelist = response.xpath('//td/text()').extract()
agelist = response.xpath('//tr/text()').extract()
sexlist = response.xpath('//a/text').extract()
#循环保存提取的内容
for i in range(len(namelist)):
item['name'] = namelist[i]
item['age'] = agelist[i]
item['sex'] = sexlist[i]
#利用yield,逐次反馈item给pipeline管道进行保存处理!
yield item
常规属性有三个:
name:自定义的爬虫名称,用于启动爬虫工程时使用,一般不会随意修改,建议设置为类属性!
allowed_domains:设置爬虫访问的域名,即访问范围,避免爬过界啊,注意它设置为list格式
start_urls:设置爬虫最先开始的地址,注意它设置为list格式,且一般为域名不带http前缀,否则可能导致无法爬到内容!
提示:
1.在爬虫代码中的yield,其实就是在函数运行的途中反馈一个请求response到调度器排队,或者反馈得到目标item到管道器存储起来,之后继续运行
2.yield它牛X的地方,就是不同于return反馈后就停止运行,而它是在运行中反馈信息,反馈后还能继续运行。
3.利用yield的函数变的自带迭代器BUFF,即变成一个生成器!或者利用yield返回函数自身,则自带了迭代循环BUFF,即变成了可自循环的函数!
4.在爬虫代码中有一些常规属性,你可以定义成类属性或者实例属性均可,由于两者的调用方式相同,所以设置成哪种都可以
5.但是请注意:如果定义成类属性,实例化后你想修改实例对象下的此属性时,要特别注意此属性并不同直接通过对象.属性=的赋值方式修改成功,而必须通过类.属性=才能修改,所以建议把爬虫的name属性设定成类属性,保证它不被轻易修改~!
总结:
scrapy的request方法很有趣,它能携带参数走。
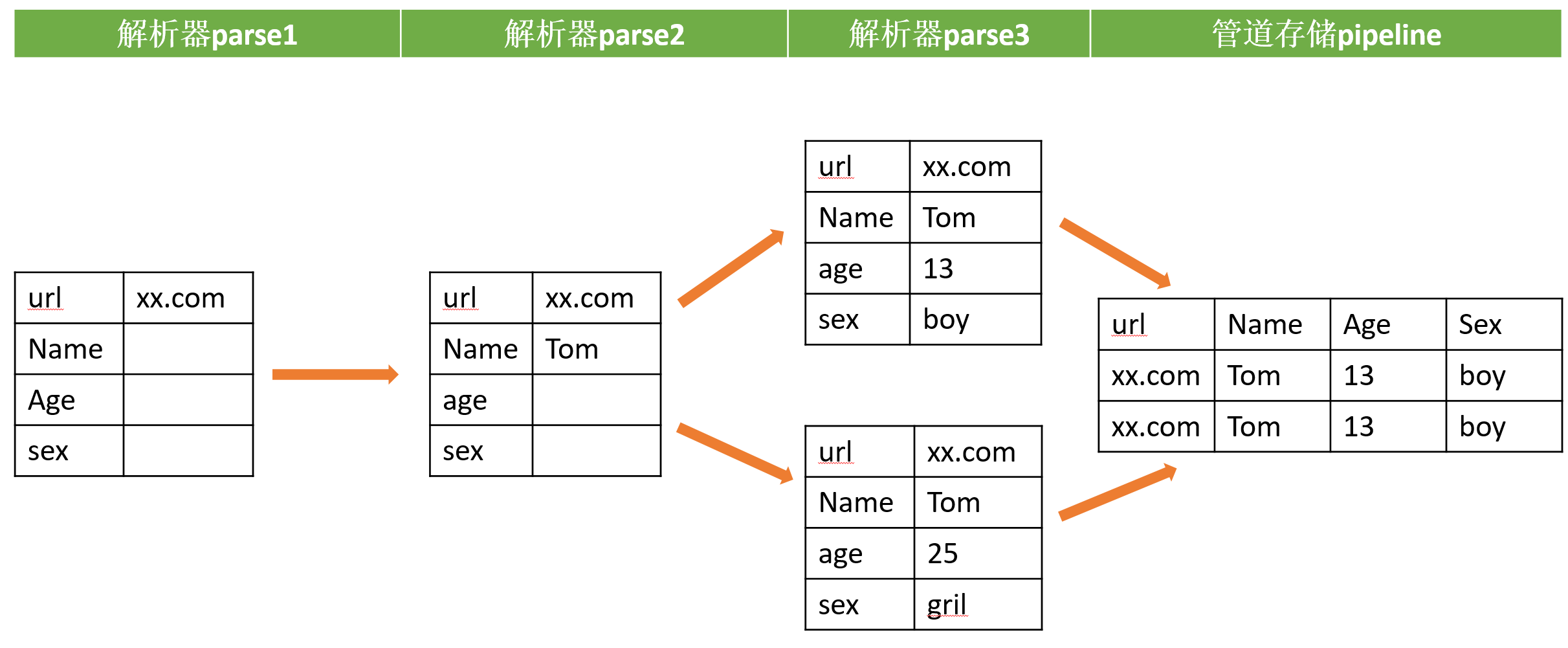
打个比喻:items是一个九宫格,yield给解析器parse1处理后就填上几个格子,然后被yield到下个解析器parse2里继续填格子,直到填满后yield给pipeline
时间不早了今天先到这,明天继续pipeline的部分
声明:本文作者原创,未经同意严禁转载
