环境:python3.6 + scrapy1.3 +pycharm2016
最近被scrapy的爬虫保存问题搞得神烦啊,虽然它自带Feed exports保存数据,但是实际在爬中文数据时会出现各种问题,在网上查了好久,好多办法都挺麻烦而且很多已经过时
下面就自己遇到的几种情况和解决方法写一下:
1、因为python3中csv的变化,导致保存的csv会隔一行出现一个空行,怎么办?
 解决方法:
解决方法:
因为scrapy自带的Feed exports我实在找不到设置csv输出参数的地方,所以只能通过自定义pipeline.py来解决了
通过设置csv方法中参数newline='',即可解决空格问题!
'''通用参考代码'''
import csv
# 此处必须设置newline='',出自python3官方文档
with open('输出.csv','w',newline='') as file:
# 定义字段名称的列表
colname = ['a','b']
# csv的字典写入方法,注意由2个参数
writer = csv.DictWriter(file,colname)
# 写入字段名称
writer.writeheader()
#写入字段数据
writer.writerow({'a':1,'b':2})
#写入字段数据,因为是字典所以不受顺序影响
writer.writerow({'b':4,'a':2})
'''scrapy中pipeline.py的设置代码'''
import csv
class DemoPipeline(object):
# 此处字段名与items.py中设置保持一致
colname = ['bocday','bocname','boctime']
def open_spider(self, spider):
# 在爬虫启动时,创建csv,并设置newline=''来避免空行出现
self.file = open('输出.csv','w',newline='')
# 启动csv的字典写入方法
self.writer = csv.DictWriter(self.file, self.colname)
# 写入字段名称作为首行
self.writer.writeheader()
def close_spider(self, spider):
# 在爬虫结束时,关闭文件节省资源
self.file.close()
def process_item(self, item, spider):
# 把每次输出的item,写入csv中
self.writer.writerow(item)
return item
2、自带Feed exports输出中文csv,excel打开会乱码,因为默认保存utf-8格式不带dom,而excel只能识别带dom的
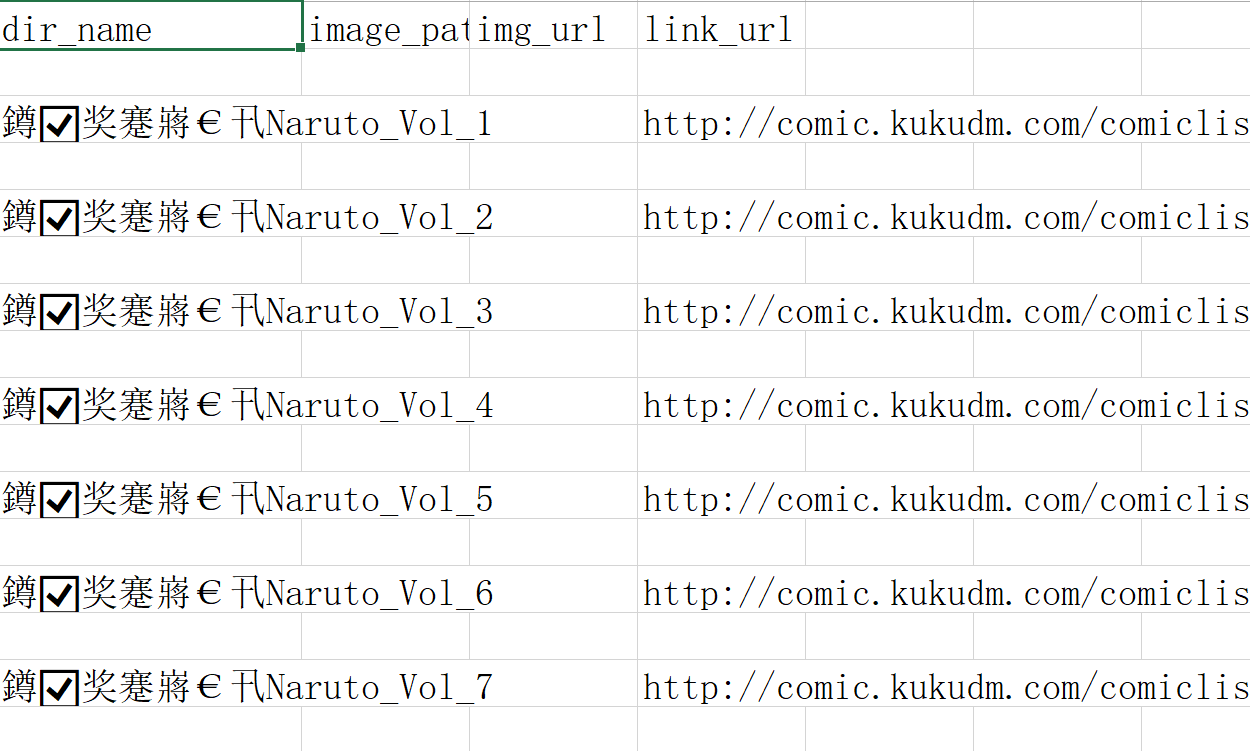 解决方法:
解决方法:
第一种方法:可以使用wps打开,测试过居然不乱码,狠不狠!
第二种方法:通过其他软件如notepad,将文件另存为utf-8带dom的格式即可
第三种方法:通过设置setting.py中的添加FEED_EXPORT_ENCODING = ‘GBK’来解决,记住是GBK才行
'''scrapy中setting.py的设置'''
FEED_EXPORT_ENCODING = 'GBK'
3、自带Feed exports输出中文json,打开还是乱码,因为json模块默认自动输出ascii编码,不是utf-8编码
解决方法:
第一种方法:设置setting.py中的FEED_EXPORT_ENCODING = 'utf-8'来解决,来自python3官方文档
第二种方法:通过编写pipeline.py来自定义输出,将json.dumps的参数ensure_ascii=False才能关闭自动识别为ascii编码
'''scrapy中pipeline.py的设置代码'''
import json
class DemoPipeline(object):
def __init__(self):
# 在构造函数时创建json文件
self.file = open('测试.json', 'w')
def process_item(self, item, spider):
# 设置参数ensure_ascii=False来解决自动编码为ascii的问题
line = json.dumps(dict(item),ensure_ascii=False) + "\n"
self.file.write(line)
return item
def close_spider(self, spider):
# 在爬虫结束时,关闭文件节省资源
self.file.close()
以后遇到问题再继续补充,欢迎提出更好的解决办法,让python的道路上少一些坑,多一些助力!
声明:作者原创文章,未经同意严禁转载
